http://ling.cuc.edu.cn/RawPub/
中国传媒大学有声媒体文本语料库是一个开放、免费使用的语料库,由中国传媒大学 国家语言资源监测与研究有声媒体中心开发。该语料库2003年开始建设,2005年上线,其后不断扩大语料规模,一直为研究者提供免费服务。为方便广大研究者使用,2016年语料库进行了第三次改版。这次改版主要加进了与原来语料规模相等、内容相同的熟语料,可以进行以词为单位或以词性及词性串为单位的词串检索。
本语料库包括2008至2013六年的34,039个广播、电视节目的转写文本,总字符数为241,316,530个,总汉字数为200,071,896字次。所有文本都进行了分词和词性标注,共计135,767,884词次。为保证语料的典型性和代表性,每年都尽可能选择那些流通度大、年度间又有一定连续性的节目文本;为便于研究者做6年间的历时语言调查,各年度的语料规模尽可能平衡。各年度语料规模如下表。
媒体语言语料库2008年-2013年各年度语料规模
| 年份 | 字符数 | 汉字数 | 文本数 |
| 2008年 | 41,915,047 | 34,344,273 | 5,731 |
| 2009年 | 41,619,011 | 34,507,007 | 5,781 |
| 2010年 | 41,599,408 | 34,300,968 | 4,359 |
| 2011年 | 38,225,239 | 31,957,770 | 5,509 |
| 2012年 | 39,078,827 | 32,602,491 | 6,593 |
| 2013年 | 38,878,998 | 32,359,387 | 6,066 |
本语料库所有语料都进行了元数据标注,既可以利用全部2亿字语料进行检索,也可以根据研究需要选定检索范围。方法是在首页右上角导航中点击“选择检索范围”,在下拉菜单中选定相应的属性项。本语料库可进行特定时间段(如2008年度、2010至2013年度)、特定媒体(广播、电视)、特定单位(如中央电视台、北京电视台、中央人民广播电台)、特定语言形式(独白、对话)、特定语体(独白形式可分为播报、谈话、解说、朗读;对话形式可分为二人谈、三人谈、多人谈)、特定领域(如新闻、经济、军事)、特定栏目(如《新闻联播》《鲁豫有约》《新闻与报纸摘要》)、特定主持人(如白岩松、陈鲁豫、崔永元)等范围的关键字检索。各属性之间有级联关系,既可以进行单独属性锁定查询,也可以进行属性间组合查询。如果“媒体”项选定了“广播”,不选择其他,就意味着下面的检索将在所有的广播语料中进行;如果“媒体”项选定了“广播”,那么在栏目项中只能选择广播的节目,不会再出现“新闻联播”这样的电视中的节目名称。如果所有的属性都没有选择,那就意味着将在全部2亿字次的语料中进行检索查询。
下面详细介绍语料库使用方法。
一、语料库功能
首页显示了语料库的基本功能。如下图所示。
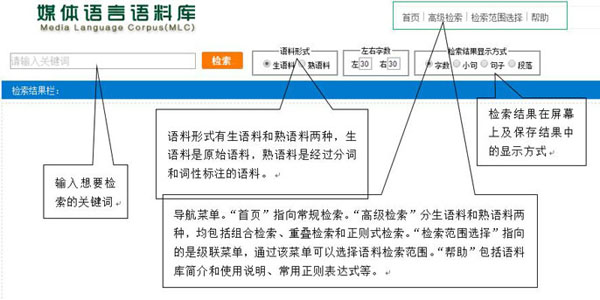
二、常规检索
首页指向的是常规检索页。语料形式包括生语料与熟语料。检索结果的屏幕显示方式包括按字数、小句、句子和段落四种。检索结果关键字居中,高亮显示,两边的字数默认各是20,用户可以根据自己需要更改,也可以选择按小句或句子、段落的形式显示,检索结果保存的格式与此相同。“检索结果栏”将给出检索范围、语料规模以及检索结果。
(一)生语料检索
即在生语料中进行关键词或字符串的简单检索。检索结果分页显示,每页显示40条。例如在检索输入框中输入“媒体”,选择检索范围为“全部语料”,检索结果如下图所示:

点击每行记录后面的“查阅”,可浏览该记录所在的文本。还可以对检索结果进行以关键字为基准的左或右排序,也可以进行二次检索。二次检索和排序按钮在检索结果的下方:

对“媒体”检索结果进行右排序,结果如下:

在二次检索中,输入“网络”,检索结果如下:

检索结果可以用文本保存下来,保存按钮在检索结果的下方:

选择“保存出处”和“加序号”后,保存结果如下:

(二)熟语料检索
熟语料是经过分词和词性标注后的语料,以词为单位进行检索,输入检索项时,词与词之间要加空格,带词性检索时,词性前面要加“/”。比如要检索做名词的“关系”,需要输入“关系/n”。词与词性在输入时可以二选一,也可以都输入。比如输入“关系 /n”表示检索所有词性的“关系”后加名词的词串,输入“关系/v /n”,则表示检索动词“关系”后面加名词词串。以输入“关系/v /n”为例,选择检索范围为“中央”,检索结果如下图所示:

三、高级检索
高级检索也包括生语料和熟语料两个模块。
(一)生语料检索
生语料检索中包括成对字串检索、重叠检索和正则表达式检索,分别举例说明如下:
1. 成对字串检索
可以检索“不但……而且”“虽然……但是”这样成对出现的词语。中间间隔的字数可以自由选择。以“不但……而且”为例,检索结果如下:

2. 重叠形式检索
可以检索的重叠形式包括AA型(看看、说说)、ABB型(一个个、一点点)、ABAB型(说着说着、特别特别)、AABB型(高高兴兴、快快乐乐)、带特定字N的ANA型(“A了A”“A不A”)、N为所有字的ANA型等。下面以AA型和ABB型为例进行说明。AA型检索结果如下:

ABB型中的A需要指定,比如指定A为“一”,则可以检索“一个个、一件件、一条条”等。检索结果如下:

需要检索“红彤彤、静悄悄、金灿灿、白花花”这样ABB重叠构词形式的朋友或者直接在生语料中检索“AA型”,或者去熟语料中检索“/z”,两者都会有垃圾串,前者可能更多一些。
3. 正则表达式检索
正则表达式具有较强地检索功能,可以进行复杂的匹配,大家可以参考本网站“帮助”菜单中的常用正则表达式。比如正则表达式“不(管|论)”表示检索“不管”或“不论”,以在句子范围内检索为例,检索结果如下:

通过正则表达式,我们可以实现较为复杂的检索,以获得我们所需要的结果,再如下面的正则表达式可以较为精确地检索“儿化词”:
(?<=[^幼少婴孤生养妻])儿(?=[^童媳女子])
该正则式比较复杂,我们分成三部分来解释:
(1)“?<=”和“?=”表示检索条件,一个表示检索内容前的条件,一个表示检索内容后的条件,比如“?<=我”表示检索内容前面必须出现“我”,“(?=我)”则表示检索内容后面必须出现“我”。
(2)“[^]”中括号内的“^”表示“非”,比如[^的地]表示不是“的”和“地”的其他字符。
(3)上面的正则表达式解释为,检索“儿”字,但是“儿”字前面不能出现字符“幼、少、婴、孤、生、养、妻”,后面也不能出现字符“童、媳、女、子”。这样就能获得比较好的“儿化词”检索结果。
选择检索范围为“北京人民广播电台”,上面的正则表达式检索的结果如下图。

(二)熟语料检索
熟语料检索中包括组合检索、重叠检索和正则表达式检索,分别举例说明如下:
1. 组合检索
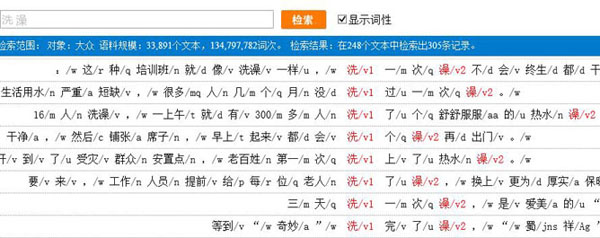
熟语料检索中的组合检索和生语料的成对字串检索在功能上有一定的相似之处,但并不完全相同,比如熟语料检索可以比较精确地检索离合词,而生语料检索所获得的检索结果就很差。以检索“洗 澡”为例,在熟语料中的检索结果如下:
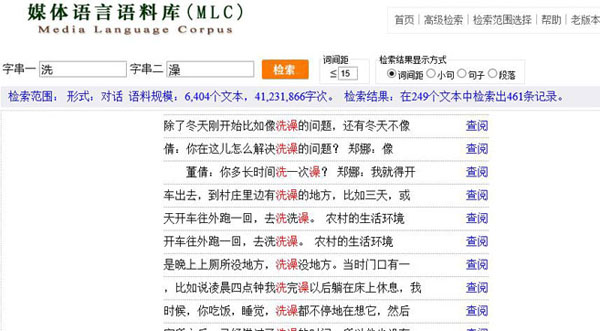
我们可以对比一下在生语料中的检索结果:
2. 重叠检索
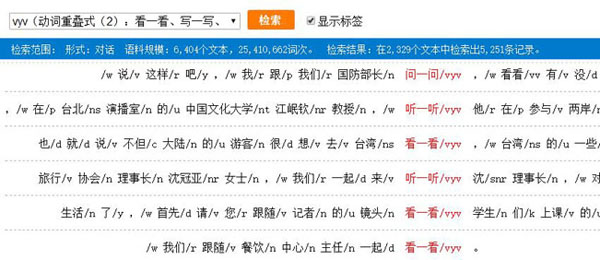
熟语料的重叠检索主要是检索分词标注后的重叠形式,包括vv、vyv等,以检索vyv为例,检索结果如下:
3. 正则表达式检索
熟语料正则表达式检索,可以比生语料获得更加理想的检索结果,比如正则表达式“一/d[^,。?]+就/d”,表示在不越过“,。?”的情况下检索“一”和“就”作为副词时的搭配情况,通过该正则表达式,可以较为精确的检索“一……就”这种表达式,而在生语料中因为没有对词性进行标记,也就不能检索“一”和“就”作为副词时的情形,所获得的语料的质量很差。以在句子范围内检索为例,在熟语料中的检索结果如下:

而在生语料中,只能这样写正则表达式进行检索“一[^,。?]+就”检索结果如下:

因此,建议对检索结果要求比较高的朋友使用熟语料及正则表达式进行检索。
四、郑重声明
1. 本语料库语料源自各电视台和广播电台节目的播出文本,版权属原作者,本语料库仅作学术研究用,如使用者违反此原则,责任自负。
2. 本语料库检索和管理系统版权属于中国传媒大学国家语言资源监测与研究有声媒体中心,请使用者在研究成果中做出声明。
3. 本语料库中的熟语料是使用国家语言资源监测与研究有声媒体中心开发的分词标注系统CUCBst6.0版进行自动分词和词性标注的结果,没有进行人工校对,所以分词和词性标注错误在所难免,仅供使用者参考。



